Archive for the ‘Technologie’ Category
Quand votre code parle une autre langue : Les pièges méconnus de la traduction
Traduire une application web peut sembler trivial à première vue. Après tout, avec les avancées de l’intelligence artificielle, une multitude d’outils facilitent grandement cette tâche. Pourtant, entre les règles de pluriel, l’ordre des mots, la direction du texte et les subtilités du contenu dynamique, traduire correctement devient vite un véritable casse-tête… à moins d’une planification rigoureuse.
Un client nous a récemment contactés pour traduire son système de gestion d’inventaire, utilisé dans des magasins à grande surface, du français vers l’anglais. Ce projet nous a permis de revisiter nos bonnes pratiques et de tomber dans quelques pièges, que nous avons dû résoudre avec ingéniosité. Voici ce qu’on a retenu de l’expérience.
Le contenu statique
Chaque environnement technologique (Laravel, Symfony, Phoenix, Rails, etc.) dispose de son propre système de traduction pour gérer le contenu statique. Sans entrer dans les détails spécifiques à chaque librairie, nous allons plutôt aborder les éléments communs qu’il est essentiel de comprendre pour bien les utiliser.
Pour commencer, Il est important de comprendre que lorsqu’on parle de contenu statique, nous parlons de texte qui est défini à l’avance à l’intérieur du code de l’application et non pas de texte qui ne change jamais. Un exemple pourrait être un libellé qui indique le nombre de résultats d’une requête:

Aussi simple ces deux mots puissent paraître, ils ont énormément de subtilités et les voici.
Le pluriel
L’un des aspects qui varie le plus d’une langue à l’autre est la manière de gérer le pluriel. Il est dangereux de supposer que les règles sont identiques, même au sein d’une même famille linguistique.
Un piège par lequel énormément de personnes se font prendre est de simplement ajouter un s lorsqu’il y a plus d’un résultat. Par exemple, en JavaScript, on pourrait l’écrire ainsi:
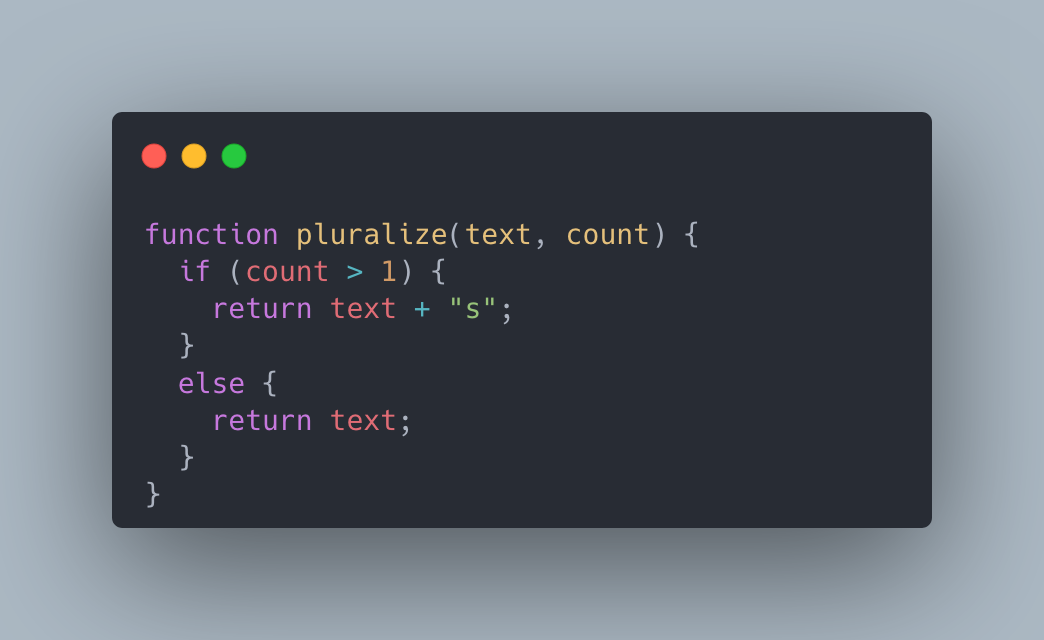
Malgré sa simplicité, ce code comporte plusieurs erreurs :
D’abord, en français comme en anglais, tous les mots ne prennent pas un « s » au pluriel. Il existe de nombreux mots irréguliers, comme « cheval » qui devient « chevaux » en français, ou « octopus » qui peut devenir « octopi » ou « octopuses » en anglais. Même en codant une logique pour gérer les exceptions, ces règles varient d’une langue à l’autre.
Ensuite, la règle grammaticale diffère pour le cas du zéro. En anglais, on accorde généralement le nom au pluriel même en l’absence d’objet, comme dans « There are no results ». Il faut donc afficher « 0 results », alors qu’en français, on écrit « 0 résultat », au singulier.
La meilleure solution consiste à utiliser les fonctions de gestion du pluriel fournies par les bibliothèques d’internationalisation. Chaque langue traduite aura donc ses propres déclinaisons de chaque chaîne de caractères accordées selon le nombre d’entrées.
Voici un exemple avec la librairie JavaScript i18n-js:
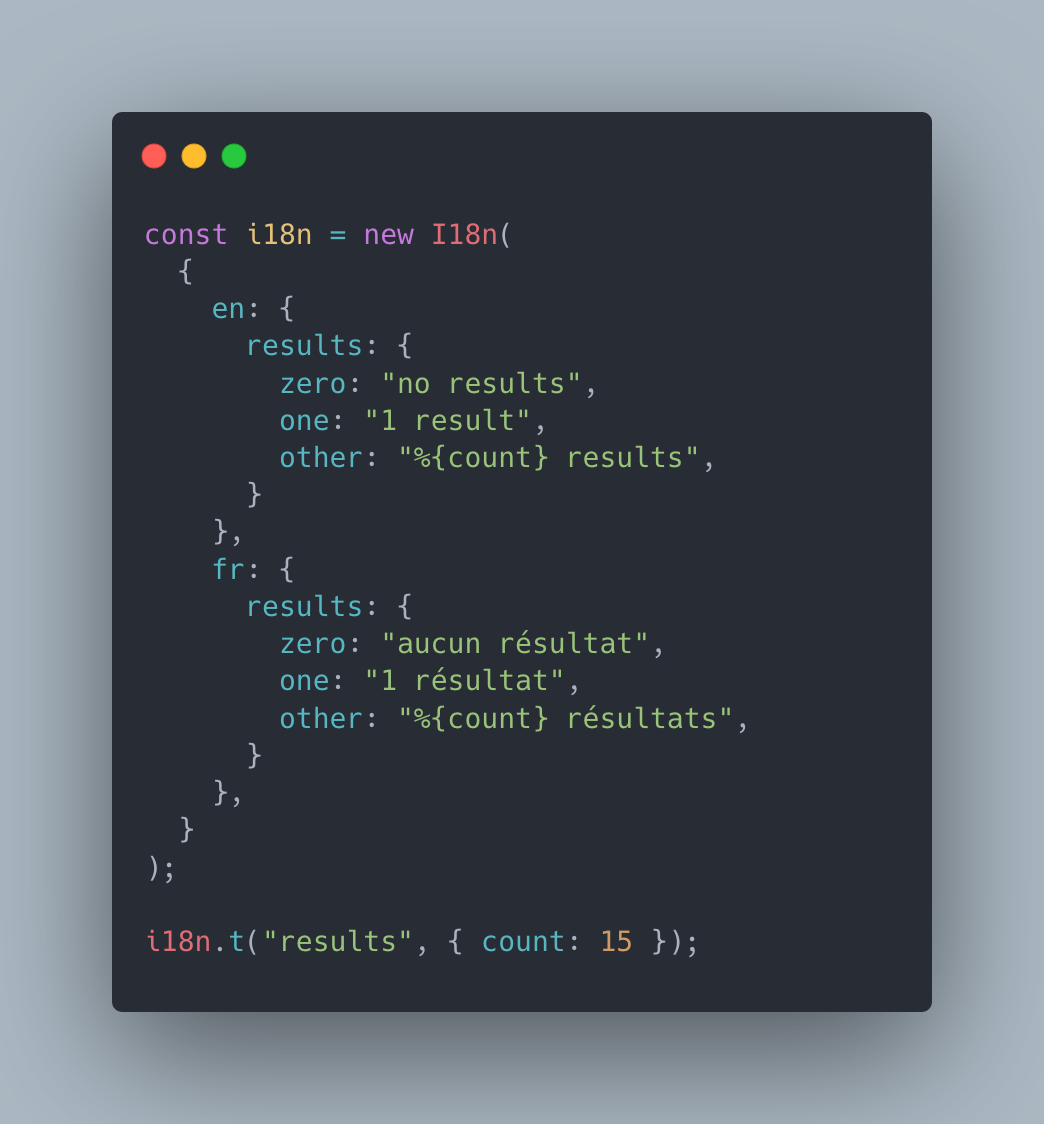
Même si les règles sont similaires pour le français et l’anglais, d’autres langues présentent bien plus de complexité. Les bibliothèques modernes permettent généralement de les gérer correctement.
Il est crucial de reconnaître que les règles grammaticales de comptage varient considérablement d’une langue à l’autre. Avant de se lancer dans la traduction, il est impératif de mener une recherche approfondie sur les règles spécifiques de la langue cible. Une compréhension solide de ces règles est essentielle pour éviter des erreurs coûteuses et garantir une communication claire et précise. Vous pouvez trouver un article (en anglais) qui explique différentes règles de pluriel ici.
L’ordre des mots
Il est facile de tomber dans le piège qui consiste à croire que toutes les langues suivent le même ordre de mots que le français ou l’anglais.
Chez Rum&Code, même si nos applications sont principalement traduites en anglais et en français, nous préparons dès le départ nos interfaces pour qu’elles puissent s’adapter facilement à d’autres langues, sans nécessiter de modifications majeures du code.
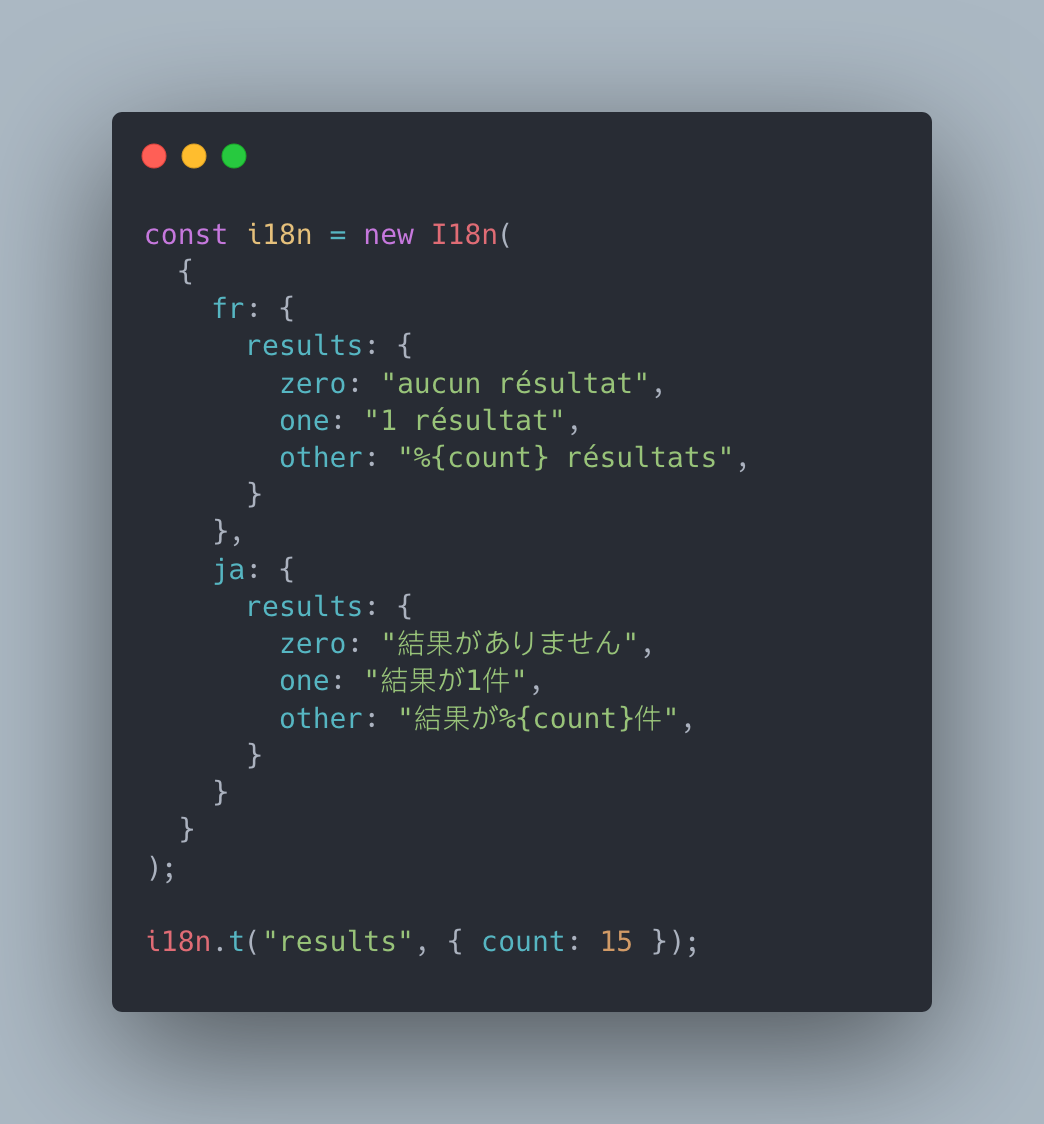
En japonais, par exemple, l’ordre des mots diffère de celui du français. Le nombre suit généralement le nom. Ainsi, l’expression « 5 résultats » se traduirait par 結果が5件 (kekka ga 5 ken). Dans cette formulation, 結果 (kekka) signifie résultats, が (ga) est une particule grammaticale, 5 représente le nombre et 件 (ken) est un classificateur numérique utilisé pour désigner des objets physiques ou des documents.
C’est pour cette raison qu’il est crucial de toujours traduire des phrases complètes et non des mots isolés. Chaque langue a sa propre structure, et il faut en tenir compte pour que le résultat soit naturel et correct.
Voici comment utiliser la librairie de notre exemple précédent avec l’ajout du Japonais:
La direction du texte
Certaines langues, comme l’arabe ou l’hébreu, s’écrivent de droite à gauche. Cette différence fondamentale de direction modifie profondément la façon dont une interface doit être conçue.
Traduire une application pour ces langues demande d’adapter l’ensemble de l’interface, et pas seulement les textes. Il faut repenser l’emplacement des éléments visuels, les formulaires, les icônes directionnelles et l’ordre de navigation.
Par exemple, sur la version arabe de la page d’accueil de YouTube, tous les éléments qui apparaissent à gauche dans la version anglaise se retrouvent à droite. Cela correspond au sens de lecture naturel de l’utilisateur.
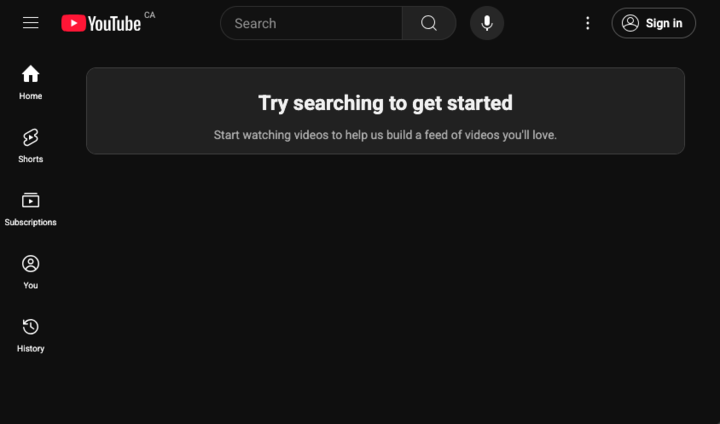
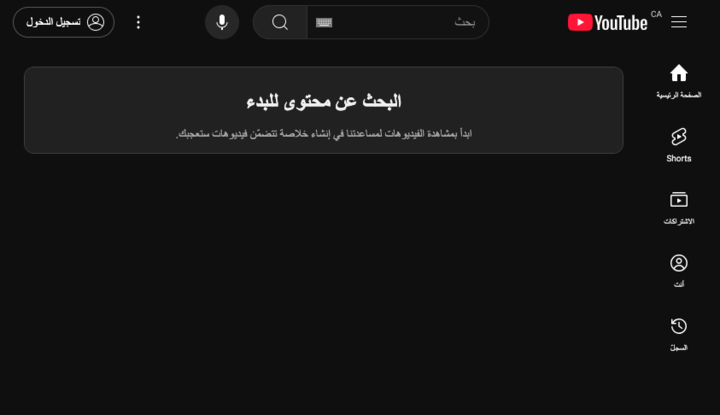
Une telle transformation nécessite souvent une refonte complète de l’interface. Cela peut devenir très complexe, surtout si la logique applicative est étroitement liée à l’interface, comme c’est souvent le cas avec des librairies telles que React ou Vue.JS.
Heureusement, CSS contient plusieurs outils tels que les propriétés logiques comme padding-inline-end pour remplacer les propriétés physiques comme padding-right. padding-inline-end ajuste le padding à la fin de la direction en ligne, s’adaptant automatiquement aux langues allant de gauche à droite et de droite à gauche. Prenez par exemple la propriété padding-inline-end: 20px cette dernière fonctionne de manière fluide et se positionne donc automatiquement à la fin de la ligne selon la direction du texte, contrairement à padding-right: 20px qui sera toujours à droite des éléments. Cette approche réduit la quantité de code à écrire pour améliorer l’adaptabilité.
Pour en apprendre plus sur la directionnalité du texte, vous pouvez vous référer à cet article sur MDN (Mozilla Developer Network): Gérer la directionnalité du texte – Apprendre le développement web | MDN
Le contenu dynamique
Les textes d’une application ne sont pas tous équivalents au niveau de la traduction. Le contenu dynamique est sans doute l’élément le plus complexe à traduire. Il s’agit de texte qui évolue au fil de l’utilisation de l’application, généré par les utilisateurs eux-mêmes ou par des systèmes externes. Contrairement au contenu statique, ce texte n’est pas défini dans le code.
Un bon exemple de contenu dynamique est l’article que vous lisez actuellement. Aucun code n’a été écrit pour l’ajouter à notre site. La traduction de contenu dynamique est complexe, car elle doit s’adapter à la logique d’affaire de l’application. Chaque type de contenu peut nécessiter une stratégie de traduction différente. Explorons trois approches, à travers le cas d’un blogue.
Utilisation d’un identifiant de langue
Une première approche consiste à ajouter un identifiant sur chaque article pour indiquer la langue dans laquelle il a été rédigé. Ainsi, chaque article est associé à une langue.
Cette méthode présente l’avantage d’être simple à mettre en œuvre. Il suffit d’ajouter une colonne dans la base de données et de filtrer les articles affichés en fonction de la langue de l’interface utilisateur.
Cependant, cette simplicité a un coût. Il faut appliquer des filtres sur chaque page où les articles sont affichés, ce qui peut devenir fastidieux selon la taille de l’application. De plus, les articles ne sont pas réellement traduits, mais existent en plusieurs versions parallèles. Si un article est partagé, rien ne garantit que le lecteur sera redirigé vers la version dans sa langue, ce qui peut nécessiter une logique supplémentaire assez lourde à maintenir.
Utilisation de colonnes traduites
Une deuxième approche pour régler le problème du contenu dynamique, peut être d’ajouter des colonnes avec un identifiant de langue. En d’autres mots, si notre modèle ressemblait à ceci:
| Id | Titre | Contenu |
| 1 | Bonjour le monde | Lorem ipsum dolor sit amet. |
| 2 | Un nouveau départ | Suspendisse et felis ornare, mollis. |
| 3 | Annonce | Nam vitae dui ultrices, maximus. |
Nous pourrions le modifier pour ajouter des colonnes traduites et indiquer la langue du contenu dans le nom de chaque colonne, par exemple, comme ceci:
| Id | Titre_FR | Titre_EN | Contenu_FR | Contenu_EN |
| 1 | Bonjour le monde | Hello world | Lorem ipsum dolor sit amet. | Mauris porttitor turpis a arcu. |
| 2 | Un nouveau départ | A new start | Suspendisse et felis ornare, mollis. | Etiam ultricies quis augue at. |
| 3 | Annonce | Announcement | Nam vitae dui ultrices, maximus. | Proin aliquet turpis ac fermentum. |
L’avantage ici, est que la gestion des articles sera significativement plus simple. Il suffit d’ajuster notre code pour lire la bonne colonne selon la langue de l’utilisateur.
Cependant, cette solution implique plusieurs contraintes:
- Il faut maintenant ajouter des colonnes à notre article à chaque fois que l’on introduit une nouvelle langue à l’application;
- Il faut adapter les formulaires de l’application pour permettre l’entrée des champs des différentes langues;
- Les articles devront être traduits au moment de leur création (ou l’on doit ajouter une gestion spéciale pour ne pas afficher les articles non-traduits);
- Il faut ajouter de la logique à l’application pour traîter les différentes colonnes.
Cette méthode est efficace si l’on ne prévoit que deux langues, mais elle devient difficilement viable dès que le nombre de langues augmente.
Utilisation d’une table de traduction
Une troisième approche serait de créer une table de traductions qui sera utilisée par toutes nos tables en base de données. Une table de ce genre contient typiquement cinq colonnes:
- le nom du modèle traduit (dans notre cas, « articles de blogue »)
- un identifiant unique pour le modèle (dans notre cas, le numéro de l’article)
- le champ traduit
- la langue de traduction
- le contenu
Cette méthode offre une grande flexibilité. Elle évite de modifier le schéma de base de données à chaque nouvelle langue, et centralise la gestion de la traduction.
Toutefois, cette flexibilité a un prix. Si la table devient trop volumineuse, elle peut ralentir l’ensemble de l’application. Il est donc essentiel de mettre en place des mécanismes de surveillance des performances et d’optimisation pour garantir la stabilité de l’application.
Les sources de traductions
Une fois votre architecture de traduction mise en place, la question devient : comment obtenir les traductions ? Collaborer avec des traducteurs externes nécessite de choisir la bonne approche selon vos besoins et votre budget.
Fichiers de traduction simples
L’approche la plus directe consiste à fournir les fichiers de traduction aux traducteurs. Le format de ces fichiers va varier selon la librairie utilisée. Voici quelques exemples de formats:
Les fichiers .po de gettext, utilisés par Elixir Phoenix:
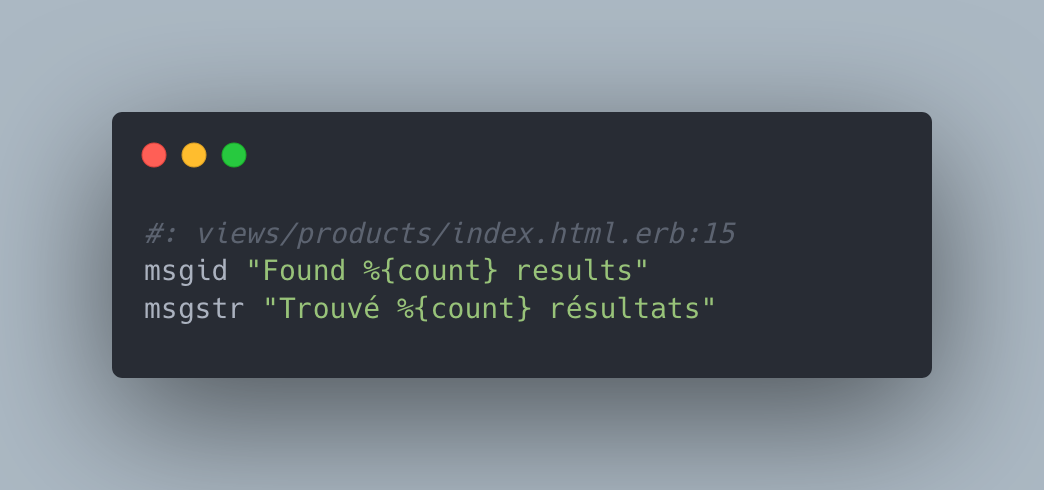
Les fichiers .yaml, utilisés par Ruby on Rails et i18n-js :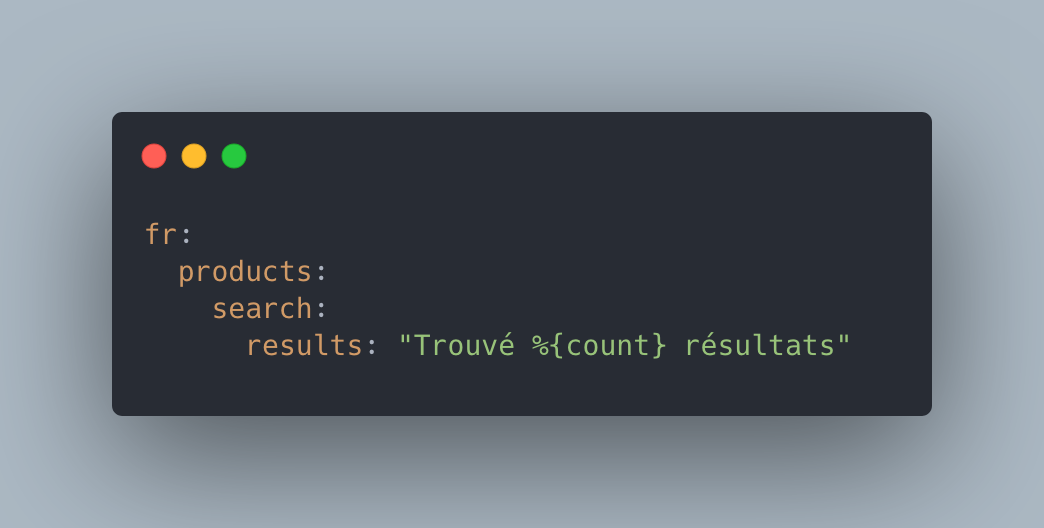
Cette méthode est simple et gratuite, mais présente certains défis : les traducteurs doivent comprendre la syntaxe technique, il n’y a pas de validation automatique, et la gestion des versions devient complexe avec plusieurs collaborateurs.
Solutions spécialisées
Pour une approche plus professionnelle, particulièrement quand il y a beaucoup de contenu à traduire, plusieurs langues cibles, ou une cadence de développement nécessitant des traductions fréquentes, des outils comme Accent (open source, auto-hébergé) offrent une interface conviviale pour les traducteurs, avec validation automatique et gestion des versions. L’inconvénient ? Il faut maintenir l’infrastructure.
Les solutions commerciales comme Crowdin éliminent la maintenance technique et offrent des fonctionnalités avancées comme la traduction assistée par IA, la gestion de mémoire de traduction, et l’intégration dans votre processus de développement. Le principal inconvénient est le coût, qui peut être un frein pour de petits projets.
Le choix dépend de votre volume de contenu, de votre budget, et de la fréquence des mises à jour. Pour un projet ponctuel, des fichiers simples suffisent. Pour un projet multilingue évolutif, un outil spécialisé devient vite indispensable.
Conclusion
Traduire une application Web ne se résume pas à un simple remplacement de mots. C’est un processus complexe qui nécessite une planification minutieuse, une compréhension profonde des nuances linguistiques et une architecture technique flexible.
En choisissant les bonnes approches pour la gestion du contenu statique et dynamique, et en étant conscient des pièges potentiels, il est possible de créer une application Web véritablement multilingue et accessible à tous. L’investissement initial dans une stratégie de traduction robuste portera ses fruits en élargissant l’accessibilité avec une portée internationale et en offrant une expérience utilisateur de qualité.
Vous envisagez de rendre votre application bilingue ou multilingue ? Nous pouvons vous accompagner pour poser les bonnes fondations dès le départ.
-Simon Landry
L’infonuagique sans complexité : naviguer dans l’univers du cloud computing
Dans notre pratique quotidienne, nous rencontrons régulièrement des clients dont les systèmes informatiques reposent encore sur des logiciels installés localement, ou on-premises*, souvent directement sur les postes individuels des utilisateurs. Ces environnements, combinant parfois une base de données rudimentaire avec des composants physiques, par exemple des feuilles Excel et des formulaires papier, représentent un défi de modernisation considérable. Aujourd’hui, nous vous proposons un voyage à travers l’évolution des infrastructures informatiques, du on-premise traditionnel aux nombreux avantages qu’offre l’infonuagique pour les entreprises de toutes tailles.
L’héritage des systèmes on-premises
Les systèmes on-premises ont longtemps constitué la norme en matière d’infrastructure informatique. Dans ce modèle, l’entreprise possède et gère l’ensemble de son infrastructure : serveurs, stockage, réseau et logiciels. Ces systèmes présentent certains avantages, notamment un contrôle total sur les données et les applications. Cependant, ils comportent également d’importants inconvénients :
- Coûts d’investissement élevés : l’achat de matériel, les licences logicielles et l’aménagement d’espaces dédiés représentent un investissement initial conséquent.
- Maintenance complexe : la gestion des mises à jour, la sécurisation et la maintenance technique nécessitent des ressources humaines spécialisées.
- Évolutivité limitée : l’adaptation aux pics d’activité ou à la croissance de l’entreprise implique souvent l’achat de matériel supplémentaire.
- Risques opérationnels : les pannes matérielles, les événements climatiques extrêmes ou les problèmes d’alimentation peuvent compromettre l’ensemble du système
Exemple concret : Jardin Bio Campanipol, une entreprise proposant des paniers hebdomadaires de produits biologiques en circuit court, utilisait initialement un système basé sur des feuilles Excel et des formulaires papier pour gérer la composition de ses paniers. Ce processus manuel était complexe, pouvait être lent, limitait la personnalisation et rendait difficile l’adaptation rapide aux disponibilités des produits de saison.
La révolution de l’infonuagique
L’infonuagique ou cloud computing** représente un changement de paradigme dans la façon dont les ressources informatiques sont délivrées, consommées et gérées. Il s’agit essentiellement de fournir des services informatiques via Internet, permettant aux entreprises d’accéder à des ressources sans avoir à investir dans leur propre infrastructure locale.
Les solutions dites SaaS (Software as a Service***) constituent le cœur de métier de Rum&Code. Nous développons des applications logicielles accessibles via un navigateur Web, sans installation locale ni maintenance pour le client. Nos solutions SaaS sur mesure répondent précisément aux besoins variés de notre clientèle, qu’il s’agisse de plateformes publiques accessibles à tous, d’outils B2B pour des échanges sécuritaires entre entreprises, ou de systèmes hybrides combinant une interface d’administration pour quelques utilisateurs privilégiés et un espace client où les utilisateurs finaux peuvent effectuer diverses opérations.
Pour déployer ces solutions, Rum&Code s’appuie également sur d’autres types de services infonuagiques, comme la plateforme-service (PaaS), qui fournit des environnements de développement complets, et l’infrastructure-service (IaaS), qui offre des ressources informatiques fondamentales telles que des serveurs virtuels et des services de stockage de données.
Les avantages décisifs de l’infonuagique
- Réduction des coûts : transformation des dépenses d’investissement en dépenses opérationnelles, avec paiement à l’usage.
- Flexibilité et évolutivité : ajustement rapide des ressources en fonction des besoins réels.
- Mise à jour automatique : entretien et mises à jour logicielles assurés par le fournisseur.
- Accessibilité mondiale : utilisation des applications depuis n’importe où, avec un accès par Internet.
- Résilience et haute disponibilité : redondance des systèmes et répartition géographique limitant les risques d’interruption.
Architecture hybride : le meilleur des deux mondes
De nombreuses entreprises doivent aujourd’hui trouver l’équilibre entre les avantages de l’infonuagique et le maintien de certains systèmes locaux, essentiels à leurs opérations, notamment en comptabilité et en gestion des stocks. Pour répondre à cette réalité, nous avons conçu des architectures hybrides qui assurent une communication fluide entre ces deux environnements.
- Applications Web infonuagiques : Interfaces modernes, accessibles de partout, gérant le flux d’informations entre fournisseurs et acheteurs.
- Systèmes comptables Locaux : Logiciels spécialisés, souvent historiques, qui demeurent critiques pour la gestion financière de l’entreprise.
Exemple de réalisation : Pour un client opérant dans la distribution de produits forestiers, nous avons créé une plateforme applicative Web qui sert d’interface entre les fournisseurs de bois (scieries, exploitants forestiers) et les acheteurs (usines de pâte à papier, fabricants de meubles). Cette application infonuagique communique en temps réel avec le logiciel de comptabilité on-premises du client via une interface de programmation sécurisée (secure API), assurant ainsi l’intégrité des données financières tout en modernisant l’expérience utilisateur et les processus métier.
Bénéfices observés
Cette approche hybride a permis d’obtenir des résultats significatifs :
- Visibilité accrue sur l’ensemble de la chaîne d’approvisionnement
- Amélioration de la trésorerie grâce à une facturation plus rapide
- Satisfaction utilisateur en hausse, tant côté fournisseurs que clients
L’évolution des infrastructures informatiques, des composantes physiques traditionnelles à l’infonuagique, ouvre la porte à des possibilités infinies pour transformer votre entreprise. Mais au-delà de la technologie, c’est l’innovation sur mesure qui fait toute la différence.
Chez Rum&Code, nous ne nous contentons pas d’adapter des solutions existantes, nous créons ce qui n’existe pas encore. Notre cocktail d’ingéniosité et de technologies vous permet de vous démarquer, avec des logiciels sur mesure qui répondent précisément à vos défis uniques.
Vous avez une vision, nous avons l’expertise pour la concrétiser. De l’idéation au produit final, chaque ligne de code est pensée pour vous propulser vers le succès.
Prêt à développer le logiciel qui n’existe pas… encore? Contactez nos experts pour transformer votre vision en réalité.
*Le logiciel on-premises est installé et exécuté sur des ordinateurs dans les locaux de la personne ou de l’organisation qui utilise le logiciel, plutôt que dans une installation distante telle qu’une batterie de serveurs ou un cloud.
**Le cloud computing, en français l’informatique en nuage, est la pratique consistant à utiliser des serveurs informatiques à distance, hébergés dans des centres de données connectés à Internet pour stocker, gérer et traiter des données, plutôt qu’un serveur local ou un ordinateur personnel. Source: Wikipédia
par Greg McDonald
Développeur senior